

打德州扑克连输八天后赢钱,总账仍亏,运气真的回来了吗?
2026年2月20日牌局分析,翻牌圈这手QTo牌如何打?
2026年2月20日
依循传统而言,过年之时是要去亲戚朋友家向长辈行拜年之礼的。然而今年情形特殊,想必大家已然不会穿梭于大街小巷,举办大规模的聚会了。
但是呢,就算是隔着屏幕,亲朋好友们聚在一起,照样能够通过“云聚会”来唠唠家常,甚至还会催你赶紧结婚。当然咯,在线上玩上几把麻将,这也算得上是一种挺不错的娱乐法子,毕竟这样做,在增进彼此交流的当口儿,能够让你的聪明才智还有运气得以施展发挥。
然而需铭记,倘若你于线上进行随机匹配对战,极易被AI “伏击”。缘由在于,近两年来,除去围棋、DOTA之外,AI已悄然无声地攻占了部分游戏领域。接下来,让雷锋网为大家梳理已被AI攻占的娱乐领域,同时也欢迎读者在文末留言补充。
AI麻将获人类顶级水平
2019年8月,微软公布了他们于麻将游戏里达成的重大进展,麻将AI“Suphx”在国际知名专业麻将平台“天凤”上荣升为十段。
“天凤”,一个日本的在线麻将竞技平台,它创立于2006年。在天凤平台,“十段”水平所代表的意义是,Suphx于麻将界具备了恰似AlphaGo在围棋界那般的地位。
Suphx于2019年3月开始登录天凤平台,历经近三个多月,和人类玩家进行了5000余场四麻对局,6月时, Suphx成功晋级天凤十段,且是首个晋级十段的AI系统。

技术简介以及策略
由136张麻将牌所构成的排列组合可能性数目繁多,加之在打牌进程里,4位玩家出牌的顺序并非是固定不变的情形(诸如碰杠之类),致使游戏树不但呈现不规则状态,并且还处于动态变化之中。
麻将 AI 难以采用 AlphaGo 那般的蒙特卡洛树搜索算法,是因这些特点所致。麻将里,每个玩家手中有 13 张牌,其中部分牌已打出,并且,其他玩家手中的牌以及剩余的底牌,全都是未知的,最多会涉及超过 120 张未知的牌,鉴于隐藏信息过多,致使游戏树的宽度极大,进而让树搜索算法基本无法施行。
对于日本麻将来讲,一轮游戏总共含有8局,最终依据8局得分的总和来开展排名,借此形成最终对段位产生影响的点数奖惩,故而AI要审时度势,把控进攻与防守的时机。
针对麻将的这些特性,进行研究的人员把整个训练进程划分成三个时期。首先是被称作“初始化”的时期,其本质是借助专家数据(由天凤平台所提供的某些公开数据)来实施有监督学习,进而获取一个初始模型。随后,在这个初始模型的基础之上,运用自我博弈的形式来开展强化学习。
处于这个阶段时,为将非完美信息博弈的难题予以克服,研究者于训练阶段,借助一些不可见的隐藏信息,以此来指引AI模型的训练走向。另外,还凭借“全盘预测”技术,构建起每轮比赛与8轮过后终盘结果之间的关联。第三个阶段是在线比赛,通过持续参与和人类玩家的对局,进而不断实现自我更新与提升。
AI 赌神升级6人局德扑完胜世界冠军
2017年年初的时候,在卡耐基梅隆大学也就是CMU的地方,举行了一场德州扑克人机大战,这场比赛那里边,4名由人类职业玩家所构成的人类大脑,输给了人工智能程序Libratus。
倘若讲那时Libratus所擅长的是一对一的领域,那么在2019年7月的Pluribus于无限制德州扑克六人局之中,将人类顶尖选手给战胜了。
Pluribus是由Facebook跟CMU合作而开发出来的,与之有关的论文发表在了《Sicence》之上。基于《Superhuman AI for multiplayer poker》这篇论文的介绍,Pluribus,其每小时能够赢得1千刀,并且仅仅只用了8天的训练时间。
技术简介以及策略
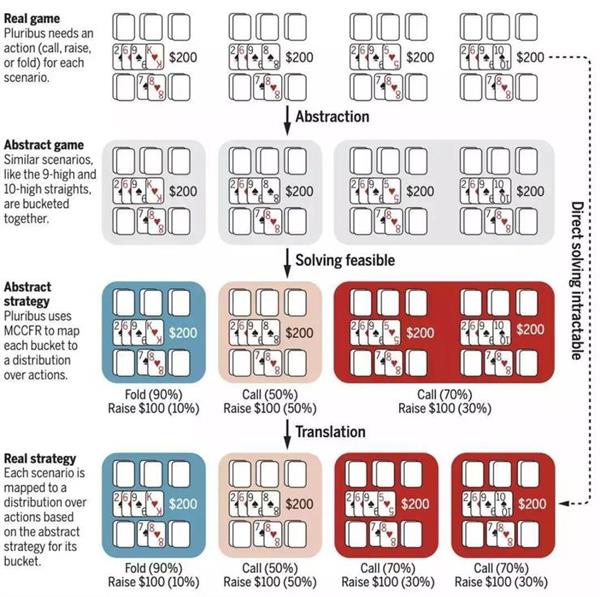
依据论文阐述,整个AI的设计划分成两个阶段,第一阶段称作蓝图策略,此阶段旨在降低游戏的复杂性,进而开展游戏抽象。游戏抽象包含两个部分,分别是动作抽象和信息抽象:动作抽象使得AI所需考量的不同动作的数量得以减少;信息抽象是将策略上相近似的牌局归集到一起,并且对这些牌局予以相同的处理。
当然,除了抽象这方面之外,这部分所采用的算法,是迭代的蒙特卡洛反事实遗憾最小化算法,也就是MCCFR。哎,在算法的每一次迭代当中,MCCFR针对玩家的某些行为以及机会的结果去进行采样。到了迭代结束的时候,玩家的策略会得到更新,接着,对每个有可能发生的情况开展概率统计,通过搜索决策树以此来决定下一步的行为。
第二阶段是这么一种情况,即深度限制搜索,在这一阶段里,Pluribus会去做实时搜索,并且制定出更精细的策略。
每个到达叶子结点的玩家,能够选择四种不同策略去进行接下来的游戏,分别是预先计算好的蓝图策略,经过修改后偏向于弃牌的蓝图策略,经过修改后偏向于跟注的蓝图策略,以及经过修改后偏向于加注的蓝图策略,算法作了这样的假设。如此这般的搜索方法,能够找出一种更为平衡的策略,进而产生更强的整体表现。
总体而言,Pluribus借助于把相近的情形整合一块儿行动,使得有关究竟是跟注、加注还是弃牌的决策要点的数目得以削减。采用蒙特卡罗虚拟遗憾最小化,把扑克博弈里树搜索的复杂程度从一个棘手难题递降至一个可求解难题。
AI “绝悟”已达到王者荣耀职业水平
2019年8月2日,在吉隆坡举行了《王者荣耀》世界冠军杯,这是该游戏最高规格的赛事,在其半决赛的特设环节里,腾讯AILab策略协作型AI“绝悟”,在与职业选手赛区联队的5v5竞技当中取得了胜利,这意味着绝悟AI已经达到了《王者荣耀》电竞职业水平。
“绝悟”这个名字,所蕴含的寓意是,有着极其出色的领悟能力,它的技术研发工作,开始于2017年12月,并且在2018年12月,通过了顶尖业余水平测试,而这个测试是由前职业选手与主播联队带来的。
技术简介以及策略
“绝悟”版本构建起了依赖“观察 -”行为运作 -“奖励”机制的极度深化的强化学习模型,既不需人类所拥有的值数据,自白板学习起始,使 AI 自身与自身开展对战,一日的训练强度竟然达到人类 440 年这般高的程度。
从0开始摸索出成功经验的 AI,勤奋学习且刻苦训练,学会了诸如怎样站位、打野、辅助保护以及躲避伤害这类游戏常识。更为惊喜的是,AI 探索出了和人类常规做法不一样的全新策略。

游戏里存在难点,此难点在于,AI需要在不完全知晓信息、具备高度复杂度的状况下,作出复杂且快速的决策。于庞大且信息不完备的地图之上,有10位参与者,他们在策略规划方面,要面临大量、不间断、即时的选择,在英雄选择方面,同样要面临大量、不间断、即时的选择,在技能应用方面,还是要面临大量、不间断、即时的选择,在路径探索方面,依旧要面临大量、不间断、即时的选择,在团队协作方面,仍然要面临大量、不间断、即时的选择,这造就了极为复杂的局面,预计存在高达10的20000次方种操作可能性,然而整个宇宙原子总数仅仅是10的80次方。
此外,与版本有关的技术方面的论文,被顶级的学术会议AAAI 2020所接纳。

写作AI 跨界下象棋
OpenAI的GPT – 2,于文本生成方面存有令人惊艳的表现,它所生成的文本,在上下文连贯性这一方面,以及情感表达这一方面,均超越了人们针对目前阶段语言模型所抱有的预期。
详细来讲,这种用于机器学习的算法,能在诸多任务方面,达成业内最优水准,并且能够依据一小段话语,自动补充出大段连贯的文本,要是有需求的话,人们能够借助一些调整,使计算机模拟出不同的写作风格。
只是,这个NLP,除去用于做阅读理解,进行问答,生成文章摘要,还有翻译之外,它还能够用来做些什么别的事儿?那些好奇心特别强烈的网友,就借着OpenAI的GPT – 2去做了一回实验。它,除了具备生成文本的能力之外,居然还能够用来下象棋,甚至还能去做音乐!
仅历经一小时训练,GPT – 2 1.5B模型便展现出国际象棋“天赋”,在下了几步棋后,虽会出现无效移动,可此次实验仍证实制造GPT – 2国际象棋引擎并非毫无可能。
GPT-2 介绍
2018年6月,OpenAI发表了论文去介绍它自己的语言模型GPT,该模型是基于Transformer架构搭建的,它采用了这样一种方式,先在大规模语料上开展无监督预训练,之后又在小得多的有监督数据集里为具体任务做到精细调节,也就是fine-tune,通过这种方式它不依赖针对单独任务的模型设计技巧,还一次性在多个任务当中取得了很好的表现。
这同样属于2018年当中自然语言处理范畴内的研究趋向,恰似计算机视觉领域里ImageNet预训练模型盛行那般。此次登场的GPT – 2乃是GPT直接的技术进阶版本,存在多10倍的模型参数数量,具体多达15亿个,并且是在多10倍的数据规模上予以训练的。
训练数据源于互联网,是 40GB 的高质量语料,具体而言,这些语料出自 Reddit 论坛里出现的高评分外链页面,高评分意指这些页面中的内容存有较高质量,如此筛选而得的语料内容有多达 800 万个页面,模型在无监督训练阶段的目标在于,给定一组由单词构成的句子而后去预测下文的下一个词。
因为数据库具备足够高的文本质量,以及足够高的多样性,并且模型拥有很高的容量,即便如此这般简单的训练目标,也得出了惊人的结果,那便是模型不但能够依据给定的文本,流畅地续写句子,甚至还可以形成成篇的文章,恰似人类续写文章那般。
模型生成文本,有时会出现失败现象,像是文字来来回回重复,有着错误的世界常识,举例来说,有时模型会写出在水下燃烧的火这种内容,还会不自然地去切换话题,然而,在成功的例子当中,模型生成的文本具备多样、全面的叙述,对事件的介绍假装有那回事一样,靠近人类的表达质量德信竞技,并且,在段落之间乃至全篇文章之中维持连续一致。


